
type
status
date
slug
summary
tags
category
icon
password
spike 模拟器是 RISC-V ISA 模拟器。可以仿真单核和多核的 RISC-V 处理器的功能模型。本文介绍 spike 模拟器的工作原理。
spike 环境安装和测试
riscv-pk 是一个代理内核,包含 bootloader,可以帮助模拟一个系统环境来运行 C 程序。
在 riscv-tests 仓库中有 RISC-V 处理器的单元测试。
完成安装后,编写一个简单的 hello.c,使用
riscv64-unknown-elf-gcc -o hello hello.c 编译,运行 spike pk hello,成功运行即为安装成功。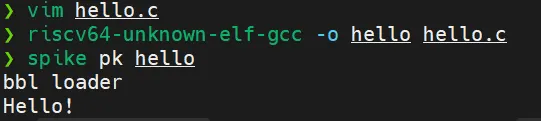
spike 仿真概述
spike 模拟器是一种 Trace-driven 模拟器。只考虑指令集的实现,而不考虑指令的执行时间。spike ,通过模拟实际代码执行过程中的软硬件行为来实现指令级别的仿真,
{% note info %} 1. Functional 模拟器,即进行功能仿真,将仿真器中运行的代码转换为主机上的二进制代码运行。如 qemu 就是这样的模拟器 2. Trace-driven 模拟器,通过记录代码执行过程中软硬件发生的变化进行仿真,可以提供指令级别的仿真。如本文介绍的 spike 3. Cycle-accurate 模拟器会提供硬件级别的仿真,即这类模拟器会实现较真实的电路连接,进行周期级别的模拟。如 Rocket-chip {% endnote %}
目录结构
spike 的源码大致分为以下几个部分:
- fdt: 为模拟器生成 device tree(核数,内存,中断等)
- fesvr: 处理 target 和 host 的交互(借助 riscv-pk)
- risc-v:risc-v 指令集的指令,模拟器的执行部分
- disasm / spike_dasm: 定义将机器码翻译为指令的命令以及寄存器的定义
- softfloat: 定义浮点数操作
- spike_main: 主程序
仿真逻辑
spike 程序的入口函数在
spike_main/spike.cc 中,首先定义参数结构体 cfg_t 并解析参数,加载仿真配置。然后声明了 sim_t 类型的对象。在 sim_t 类的定义中定义了 run 函数和仿真时的参数。在解析了命令行参数,配置了基本的变量后,spike 对内存和指令进行了初始化,在
register_extension(e()) 函数中,spike 在程序中注册了指令。之后,程序由
sim_t::run() 函数开始,接下来分析到的文件都位于 riscv 文件夹中,函数的调用路径如下: sim_t::run() ⇒ htif_t::run() ⇒ htif_t::start() ⇒ sim_t::idle ⇒ sim_t::step() ⇒ proccessor_t::step()在
proccesor_t::step() 中,spike 进行一个周期的指令模拟,执行模拟的部分程序如下所示:应当是在
execute_insn_logged() 函数中执行了本周期的指令,继续追踪execute_insn_logged() 函数可以找到 fetch.func(p, fetch.insn, pc),继续跳转无果,所以想要继续分析就要找到 fetch.func 是什么含义。回去观察 proccesor_t::step(),可以发现 fetch 来自于 mmu->load_insn(pc),追踪到 mmu 的取指函数 refill_icache,在该函数中,指令由 mmu 从内存中取出:找到定义
insn_fetch_t fetch = {proc->decode_insn(insn), insn};,其中 proc 是 processor_t 类型的变量,于是再次回到 proccesor_t 查看 decode_insn 函数:并找到
desc 变量类型的定义:可以看出在上面的函数中,
desc 从 instructions 中获取指令信息。追踪该数组发现是在程序开始时注册指令时进行的初始化,由此得知,在该函数中得到了执行指令的信息并返回了 insn_fetch_t 类型的变量,该类型定义如下:可见其本质是一个函数指针,对照
fetch.func(p, fetch.insn, pc) 使用 processor_t * 获取处理器核对象,传入指令 insn_t 和 pc 值,使模拟的处理器核对象执行该条指令。至此,spike 模拟器完成了一条指令的仿真。
指令解析
在 riscv/insn 中,spike 为每一条指令都准备了一个头文件用来指定指令的行为。而指令的编码则定义在 riscv/encoding.h 中,encodeing 文件使用 riscv-opcodes 自动生成。在 riscv/decode.h 中定义了指令对应的类,其中实现了对指令的解析。
spike 模块
fesvr (RISC-V Frontend Server) 与 pk (proxy Kernel)
在前面的章节简单梳理了 spike 本身的工作逻辑,但是在介绍仿真过程时还留下了一些问题,比如:
- 仿真时的程序是如何读入仿真器的?
- 仿真器地址与主机地址如何转换?
而这些问题就是 fesvr 和 pk 完成的任务。
fesvr 曾经是一个独立的项目,专门处理 spike 模拟器与主机之间的交互,如今已经完全合并到了 spike 之中。pk 现在依然是一个独立的项目,实现了一个代理内核包含 bootloader 和一些系统调用,可以理解为一个轻量的操作系统。本节就借助回答上面两个问题来介绍 fesvr 和 pk。
让我们回顾一下仿真函数的调用路径:
sim_t::run() ⇒ htif_t::run() ⇒ htif_t::start() ⇒ sim_t::idle ⇒ sim_t::step() ⇒ proccessor_t::step() 可以看到在 sim_t::run() 调用了 htif_t::run() 后,经过 htif 部分的处理,又回到了 sim 部分。而 htif 是 Host/Target Interface,主机/目标交互接口,是 fesvr 的一部分。进入
htif_t::run,可以看到该函数的逻辑非常简单, htif_t::run() ⇒ htif_t::start() ⇒ while 循环进行仿真 ⇒ htif_t::stop() 进入 htif_t::start() 函数可以看到其调用了 htif_t::load_program() 函数。加载程序
htif_t::load_program() 中,std::map<std::string, uint64_t> symbols = load_payload(targs[0], &entry); 通过 load_payload 程序读取了 elf 文件(load_payload 的原理暂不讨论)。从符号表中获取了 tohost_addr 和 fromhost_addr。在这里建立起了模拟器与主机之间的关系,根据上面找到的取指指令 insn_bits_t insn = from_le(*(uint16_t*)(tlb_entry.host_offset + addr)); 可以看出 fesvr 是利用了模拟器本身也在主机内存中运行的便利,通过地址的转换直接在内存中取值。以上就回答了第一个问题,fesvr 使用
htif_t::load_program() 加载了可执行文件,并记录了模拟器与主机的转换地址。地址转换
在上述过程中我们已经找到了 fesvr 如何将模拟器中的数据与主机联系起来。但是在 spike 中,并没有与
tohost 和 fromhost 相关的代码,使用 riscv64-unknown-elf-readelf 查看编译出的可执行文件的符号表也没有找到相关的信息。这时想起在运行 hello 时,还需要 riscv-pk 工具,查看 pk 的代码,在 machine 文件夹中找到了 htif 相关的文件,在其中找到了关于 tohost 和 fromhost 的定义。
而在 spike 的主程序文件 spike.cc 中,可以找到在仿真开始前,spike 对 kernel 的初始化以及
kernel_offeset 的定义:至此可以看出,spike 和 pk 依靠 htif 进行通信,由 fesvr 获取主机地址和内核的偏移量,pk 计算
tohost_addr 和 fromhost_addr,完成了主机与模拟器间地址的转换。使得模拟器可以在主机上运行,并且完成一些系统调用(如 print, scanf 等)。设备树
设备树是一种描述硬件的数据结构。在 spike 中,设备树的具体实现位于 riscv/dts.cc 和 fdt 文件夹中。接下来借助 spike 的输出简单介绍一下 spike 的设备树。使用安装测试中的 hello 文件进行测试,执行
spike --dumpdts hello 即可看到设备树的输出。这个输出就是 pk 的虚拟 RISC-V SoC 的配置了,根据以上输出可以画出它的设备树,
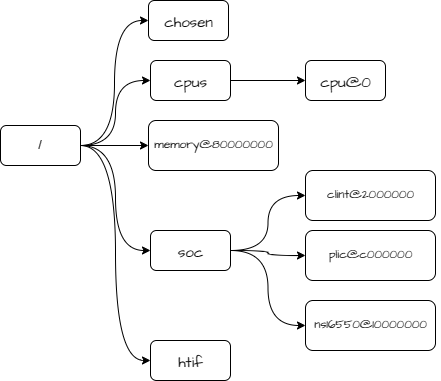
RISC-V SoC device tree
可以看到节点一般是以 node-name@unit_address 的形式出现的,若某个节点没有地址或者寄存器,也可以不要 unit-address,比如 htif。根节点既没有 node-name,也没有 unit_address,他被定义为 “/”。
几个重要的参数
下面介绍一下出现在设备树中比较重要的参数。
#address-cells, #size-cells, reg
#address-cells 和 #size-cells 值为无符号 32 位整型,用来描述子节点的地址信息,一般与 reg 一起表示地址信息。
reg 属性的值一般是 (address, length) 对,用于描述设备地址空间资源信息,一般都是某个外设的寄存器地址范围信息。reg 的格式一般为:
#address-cells 表示在 reg 属性中,地址信息占用的长度。#size-cells 表示在 reg 信息中,长度信息占用的长度。
举个栗子(没有实际意义):
device_type
目前的设备树中,该属性只用于 cpu 和 memory 节点中。
status
表示设备状态,值为字符串,比如 cpu@0 节点的 status 为 “okay”。
compatible
compatible 属性也叫做“兼容性”属性,是一个字符串列表,用于将设备和驱动绑定起来,格式为:
以上是标准的设备树中较为重要的设备信息,在 spike 中还定义了诸如 mmu-type,interrupt-controller 等硬件细节。
几个重要的子节点
memory
所有设备树都需要一个 memory 设备节点,它描述了系统的物理内存布局。如果系统有多个内存块,可以创建多个 memory 节点,或者可以在单个 memory 节点的 reg 属性中指定这些地址范围和内存空间大小。memory 节点对于 reg 属性的解释会使用根节点的 #address-cells 和 #size-cells 的值。
chosen
chosen 并不是一个硬件设备,添加 chosen 节点主要是为了 uboot 向 Linux 内核传递数据,重点是 bootargs 参数。
cpus
cpus节点下有1个或多个cpu子节点, cpu子节点中用reg属性用来标明自己是哪一个cpu,所以对于 cpus:
- #address-cells 指在子节点中,用多少个 32 位无符号数表示自己的地址。
- #size-cells 必须为0
综上所述,设备树就是对硬件的一套简洁的描述方式,用来直接将硬件细节传递给操作系统,从而避免在内核中写入过多的类似编码。
TodoList
mmu 模块设备支持 & IO 实现指令拓展
- 作者:Light-ly
- 链接:notion.light-liuyi.top/article/riscv-spike-code-analytic
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。